Alarm rates that exceed an operator’s ability to manage them are common. This article explains the causes for high alarm rates and how to address them
Modern distributed control systems (DCS) and supervisory control and data acquisition (SCADA) systems are highly capable at controlling chemical processes. However, when incorrectly configured, as is often the case, they also excel at another task — generating alarms. It is common to find alarm rates that exceed thousands per day or per shift at some chemical process industries (CPI) facilities (Figure 1). This is a far greater number than any human can possibly handle successfully. This article examines the nature of the problem and its cure.
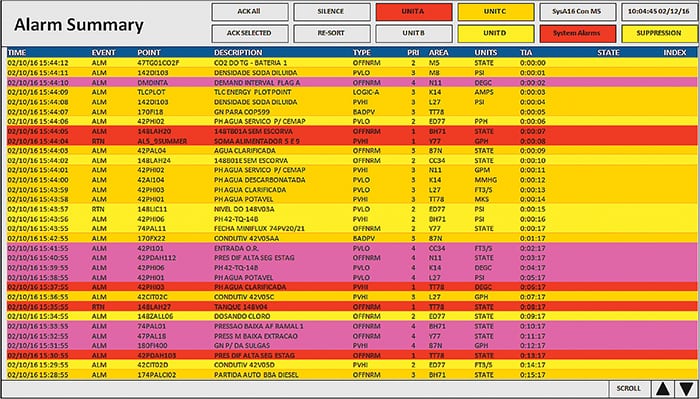
Figure 1. Alarm rates on the order of thousands per day are not uncommon in some CPI facilities
The alarm system acts as an intentional interruption to the operator. It must be reserved for items of importance and significance. An alarm should be an indication of an abnormal condition or a malfunction that requires operator action to avoid a consequence. Most alarm systems include interruptions that meet this definition, but also many miscellaneous status indications that do not.
A major reason for this situation is that control system manufacturers make it very easy to create an alarm for any imaginable condition. A simple analog sensor, such as one for temperature, will likely have a dozen alarm types available by simply clicking on check boxes in the device’s configuration. Without following sound alarm-management principles, the typical results are over-alarming, nuisance alarms, high alarm rates and an alarm system that acts as a nuisance distraction to the operator rather than a useful tool.
Whenever the operators’ alarm-handling capacity is exceeded, then operators are forced to ignore alarms, not because they want to do so, but because they are not able to handle the number of alarms. If this is the case, the average, mean, median, standard deviation, or other key performance indicators (KPIs; see Part 1, p. 50) for alarms do not matter, because plant managers have no assurance that operators are correctly ignoring inconsequential alarms or are paying attention to the ones that matter. This situation contributes to many major accidents.
Alarm rates
The International Society of Automation (ISA; Research Triangle Park, N.C.; www.isa.org) Standard 18.2 on alarm management identifies the nature of the problem and offers a variety of assessment measurements. An important measurement is the rate of alarms annunciated to a single operator.
Figure 2 shows an overloaded alarm system. The difference between the two lines is the effect of including or removing only 10 individual high-rate nuisance alarms. This is a common problem that is discussed later in the article.
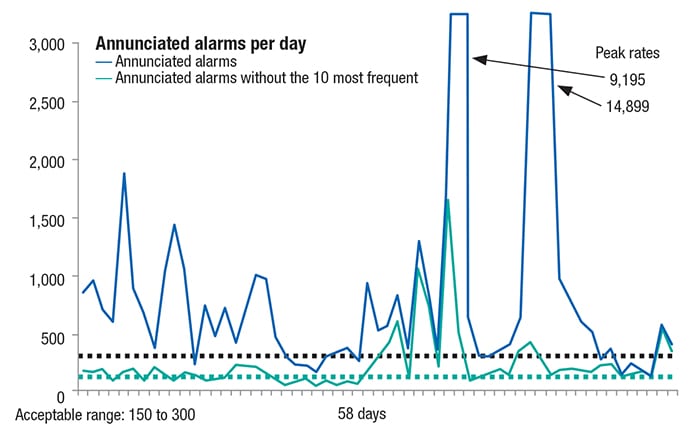
Figure 2. Removing a small number of high-rate alarms can have a large effect on the alarm system’s overall profile
To respond to an alarm, an operator must detect the alarm, investigate the conditions causing the alarm, decide on an action, take the action and finally, monitor the process to ensure that the action taken resolves the alarmed condition. These steps take time and some must necessarily be executed sequentially. Others can be performed in parallel as part of a response to several alarms occurring simultaneously.
Given these steps, handling one alarm in 10 minutes (that is, approximately 150 over a 24-h period) can generally be accomplished without the significant sacrifice of other operational duties, and is considered likely to be acceptable. A rate greater than 150 per day begins to become problematic. Up to two alarms per 10-minute period (~300 alarms/day) are termed the “maximum manageable.” More than that may be unmanageable.
The acceptable alarm rates for small periods of time (such as 10 minutes or one hour) depend on the specific nature of the alarm, rather than the raw count. The nature of the response varies greatly in terms of the demand upon the operator’s time. The duration of time required for an operator to handle an alarm depends upon the particular alarm.
As an example, consider a simple tank with three inputs and three outputs. The tank’s high-level alarm occurs. Consider all of the possible factors causing the alarm and what the operator has to determine:
- Too much flow on inlet stream A, or B or C
- Too much combined flow on streams A-B, A-C, B-C or A-B-C
- Not enough flow on outlet stream D, E or F
- Not enough combined flow on streams D-E, D-F, E-F or D-E-F
- Several more additional combinations of the above inlet and outlet possibilities.
The above situation takes quite a while to diagnose, and involves observing trends of all of these flows and comparing them to the proper numbers for the current process situation. The correct action varies highly with the proper determination of the cause or causes. The diagnosis time varies based upon the operator’s experience and involvement in previous similar situations.
Process control graphics (human-machine interfaces; HMIs) play a major role in effective detection of abnormal situations and responses to them. Using effective HMIs, an operator can quickly and properly ascertain the cause and corrective action for an abnormal situation. However, the quality of the HMI varies widely throughout the industry. Most HMI implementations are little more than a collection of numbers sprinkled on a screen while showing a piping and instrumentation diagram (P&ID), making diagnosis much more difficult. For more discussion on this topic, search the Internet for the term “High-Performance HMI,” or see the comprehensive white paper cited in Refs. 1 and 2.
As a result, the diagnosis and response to a simple high-tank-level alarm becomes quite complicated. Given the tasks involved, it might only be possible to handle a few such alarms in an hour.
Other alarms are simpler, such as, “Pump 412 should be running but has stopped.” The needed action is very direct: “Restart the pump, or if it won’t restart, start the spare.” Operators can handle several such alarms as these in 10 minutes. It takes less time to assess and work through the situation.
Response to alarm rates of 10 alarms per 10 minutes (the threshold of a “flood”) can possibly be achieved for short periods of time — but only if the alarms are simple ones. And this does not mean such a rate can be sustained for many 10-minute periods in a row. During flood periods (Figure 3), operators are likely to miss important alarms. Alarm rates per 10 minutes into the hundreds or more, lasting for hours, are common. What are the odds that the operator will detect the most important alarms in such a flood? Alarm floods can make a difficult process situation much worse, and are often the precursors to major upsets or accidents.
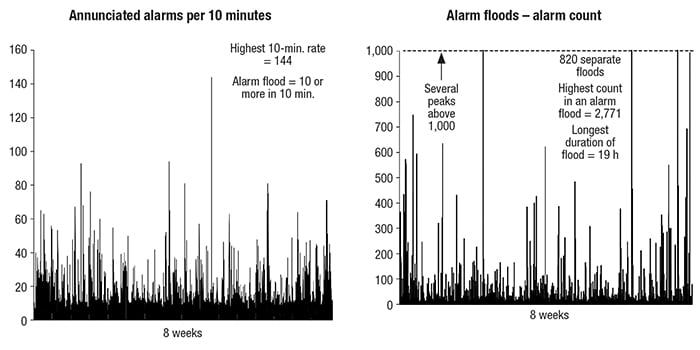
Figure 3. During alarm flood periods, it is very likely that operators will miss important alarms
Averages can be misleading
Alarm performance should generally be viewed graphically rather than as a set of averages. Imagine that during one week, your alarm system averaged 138 alarms per day and an average 10-minute alarm rate of 0.96. That would seem to be well within the bounds of acceptability. But the data producing those average numbers could look like that shown in Figure 4.
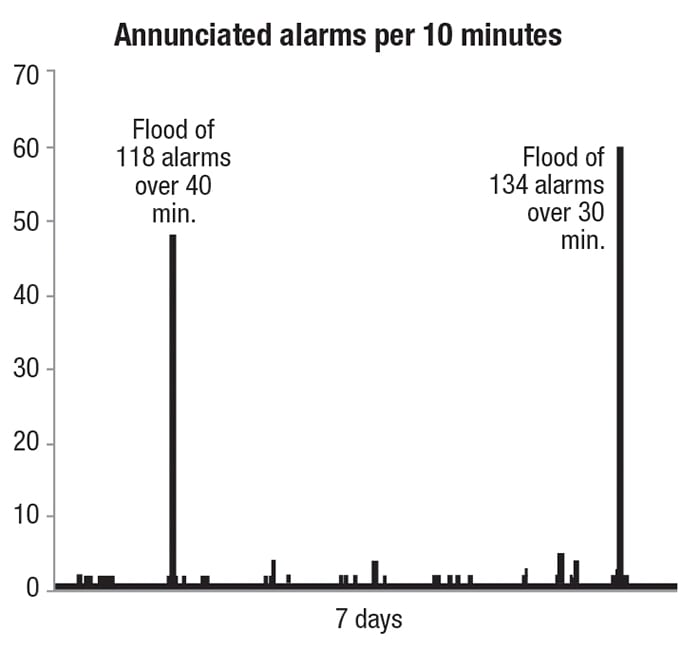
Figure 4. Different alarm data can generate similar average alarm rates, and the average rate may not tell the full story
The first flood lasted 40 minutes with 118 alarms. The second flood lasted 30 minutes with 134 alarms. How many of those alarms were likely to be missed? A simplistic answer (but good enough for this illustrative purpose) is to count the alarms that exceed 10 within any 10-minute period for the duration of each flood, which, for the current example, would be a total of 182. In other words, despite these seemingly great averages (many plant managers would consider these averages to be strong alarm-system performance and that they would be happy to achieve), the alarm pattern still puts the operators in the position of likely missing almost 200 alarms. Missing so many alarms can result in improper operator actions and undesirable consequences — perhaps quite significant ones.
It is easy to plot such data, as in Figure 5. During an eight-week period, almost 21,000 alarms were likely to be missed. A weekly view of such data in this way will likely gain the attention of management, whereas viewing the overall averages alone would indicate that things are satisfactory when they are not.
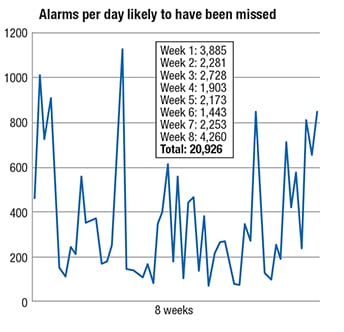
Figure 5. Despite sound averages for alarm rates, it can still be the case that many alarms could be missed during alarm flood periods
Bad actor alarm reduction
Many types of nuisance alarm behaviors exist, including chattering (rapidly repeating), fleeting (occurring and clearing in very short intervals), stale, duplicate and so forth. Alarms with such behaviors are called “bad actors.” The most common cause of high alarm rates is the misconfiguration of specific alarms, resulting in unnecessarily high alarm occurrence rates. Commonly, 60–80% of the total alarm occurrences on a system come from only 10–30 specific alarms. Chattering alarms and fleeting alarms are both common. Simply ranking the frequency of alarms will identify the culprits. Finding and correcting these rate-related nuisance behaviors will significantly reduce alarm rates with minimal effort.
In the example data shown in Figure 6, 76% of all alarm occurrences came from only 10 individual configured alarms. In fact, the top two alarms make up 50% of the total load, with about 48,000 instances in 30 days. Alarms are never intentionally designed to annunciate so frequently, but they do. In this configuration, they would not perform a useful function; rather, they would be annoying distractions.
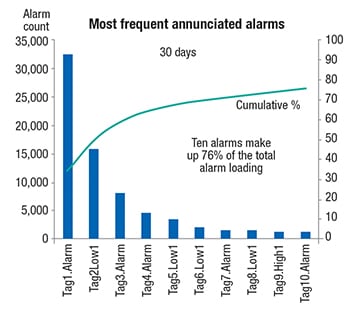
Figure 6. In many cases, the most frequently occurring alarms make up the bulk of the total alarm load
Many of these were chattering alarms. In summarizing 15 alarm-improvement projects at power plants, the author’s employer found that 52% of all alarm occurrences were associated with chattering alarms. Proper application of alarm deadband and alarm on-delay/off-delay time settings usually corrects the chattering behavior. The calculations for determining those settings are straightforward (but beyond the scope of this article). Much more detailed information for solving all types of nuisance alarm problems can be found in Ref. 3.
Alarm rationalization
The other cause of high alarm rates requires more effort to address. Most alarm systems are initially configured without the benefit of a comprehensive “alarm philosophy” document. This document sets out the rules for determining what kinds of situations qualify for alarm implementation. It specifies methods for consistently determining alarm priority, controlling alarm suppression, ongoing performance analysis, management of change, and dozens of other essential alarm-related topics.
Systems created without such a document are usually inconsistent collections of both “true alarms,” along with many other items, such as normal status notifications that should not use the alarm system. Such non-alarms diminish the overall effectiveness of the system and diminish the operator’s trust in it. They must be purged. While it may be easy to spot things that clearly have no justification for being alarms by looking at the list of most frequent alarms, a comprehensive alarm rationalization is needed to ensure the consistency of the overall alarm system.
With alarm rationalization, every existing alarm is compared to the principles in the alarm philosophy document and is either kept, modified or deleted. Setpoints or logical conditions are verified. Priority is assigned consistently. New alarms will be added, but the usual outcome of rationalization is a reduction in configured alarms by 50–75%. Since the alarm-management problem was identified in the early 1990s, thousands of alarm systems have undergone this process and achieved the desired performance.
After the bad actor reduction and the rationalization steps, alarm rates are usually within the target limits. A typical result is shown in Figure 7. Significant process upsets, particularly equipment trips, may still produce some alarm floods, which can be addressed in Step 6 listed below.
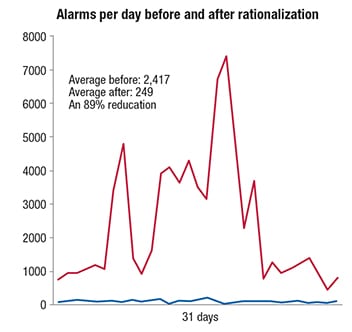
Figure 7. Alarm rates can usually be brought into target limits by alarm rationalization and bad-actor reduction steps
The 2009 publication of the ISA-18.2 Alarm Management Standard includes both having an alarm philosophy document and performing alarm rationalization as mandatory items. For a comprehensive white paper on understanding and applying ISA-18.2, see Ref. 4.
Alarm management work process
There is an efficient seven-step plan for improving an alarm system, proven in more than 1,000 improvement projects in plants throughout the world. Steps 1–3 are simple, and often done simultaneously as an initial improvement effort with fast, high-impact results.
Step 1: Develop, adopt and maintain an alarm philosophy. A comprehensive guideline for the development, implementation and modification of alarms, an alarm philosophy establishes basic principles for a properly functioning alarm system. It provides an optimum basis for alarm selection, priority setting, configuration, response, handling methods, system monitoring and many other topics.
Step 2: Collect data and benchmark the alarm system. Measuring the existing system against known, best-practice performance indicators identifies specific deficiencies, such as various types of nuisance alarms, uncontrolled suppression, and management-of-change issues. A baseline is established for improvements measurement.
Step 3: Perform “bad actor” alarm resolution.Addressing a few specific alarms can substantially improve an alarm system. Bad actor alarms, which can render an alarm system ineffective, are identified and corrected to be consistent with the alarm philosophy. An ongoing program to identify and resolve nuisance alarms is necessary.
Step 4: Perform alarm rationalization. Alarm rationalization is a comprehensive review of the alarm system to ensure it complies with the principles in the alarm philosophy. This team-based effort re-examines existing and potential alarms configured on a system. Alarms to be added, deleted and reconfigured are identified, prioritized and documented. The resulting alarm system has fewer configured alarms and is consistent and documented with meaningful priority and setpoint values.
Step 5: Implement alarm audit and enforcement technology. Once an alarm system is rationalized, its configuration must not change without authorization. Because DCS systems can be easily changed by a variety of sources, they often require mechanisms that frequently audit (and enforce) the approved configuration.
Step 6: Implement advanced alarm management. Certain advanced alarm capabilities may be needed on some systems to address specific issues. For example, state-based alarming monitors the current process state, and alarm settings are dynamically altered in predetermined ways to match the alarming requirements of that process state. Alarm flood suppression temporarily eliminates the expected and distracting alarms from a unit trip, leaving the relevant alarms that assist the operator in managing that post-trip situation. Such advanced methods can ensure that the alarm system is effective even in abnormal situations.
Step 7: Control and maintain the improved system. An effective alarm system requires an ongoing and typically automated program of system analyses that may include KPI monitoring and the correction of problems as they occur.
Concluding remarks
The various problems with alarm systems are well recognized and there are proven solutions to these problems. The principles from these solutions have been successfully applied to thousands of alarm systems worldwide. The alarm management body of knowledge is mature. Solving alarm-system problems simply requires the will and effort to do so.
Edited by Scott Jenkins
References
1. Hollifield, B. and Perez, H. Maximize Operator Effectiveness: High Performance HMI Principles and Best Practices, Part 1 of 2. PAS Inc., Houston, 2015.
2. Hollifield, B. and Perez, H. Maximize Operator Effectiveness: High Performance HMI Case Studies, Recommendations, and Standards, Part 2 of 2. PAS Inc., Houston 2015.
3. Hollifield, B. and Habibi, E. The Alarm Management Handbook, 2nd Ed., PAS Inc., Houston 2010.
4. Hollifield, B. Understanding and Applying the ANSI/ISA 18.2 Alarm Management Standard. PAS Inc., Houston 2010.
Author
 Bill Hollifield is the principal consultant at PAS Inc. (16055 Space Center Blvd., Suite 600, Houston, TX 77062; Phone: 281-286-6565; Email: bhollifield@pas.com). He is responsible for alarm management and high-performance HMI. He is a member of the ISA-18 Alarm Management committee, the ISA-101 HMI committee, and is a co-author of the Electric Power Research Institute’s (EPRI) Alarm Management Guidelines. Hollifield is also coauthor of the Alarm Management Handbook and The High Performance HMI Handbook, along with many articles on these topics. Hollifield has a dozen years of international, multi-company experience in all aspects of alarm management and effective HMI design consulting for PAS, coupled with 40 years overall of industry experience focusing on project management, chemical production and control systems. Hollifield holds a B.S.M.E. from Louisiana Tech University and an MBA from the University of Houston. He’s a pilot and has built his own plane (with a high-performance HMI).
Bill Hollifield is the principal consultant at PAS Inc. (16055 Space Center Blvd., Suite 600, Houston, TX 77062; Phone: 281-286-6565; Email: bhollifield@pas.com). He is responsible for alarm management and high-performance HMI. He is a member of the ISA-18 Alarm Management committee, the ISA-101 HMI committee, and is a co-author of the Electric Power Research Institute’s (EPRI) Alarm Management Guidelines. Hollifield is also coauthor of the Alarm Management Handbook and The High Performance HMI Handbook, along with many articles on these topics. Hollifield has a dozen years of international, multi-company experience in all aspects of alarm management and effective HMI design consulting for PAS, coupled with 40 years overall of industry experience focusing on project management, chemical production and control systems. Hollifield holds a B.S.M.E. from Louisiana Tech University and an MBA from the University of Houston. He’s a pilot and has built his own plane (with a high-performance HMI).